Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- arXiv
 Proactive Assistant Dialogue Generation from Streaming Egocentric VideosYichi Zhang, Xin Luna Dong , Zhaojiang Lin , Andrea Madotto , Anuj Kumar , Babak Damavandi , Joyce Chai , and Seungwhan MoonIn arXiv , Jun 2025
Proactive Assistant Dialogue Generation from Streaming Egocentric VideosYichi Zhang, Xin Luna Dong , Zhaojiang Lin , Andrea Madotto , Anuj Kumar , Babak Damavandi , Joyce Chai , and Seungwhan MoonIn arXiv , Jun 2025Recent advances in conversational AI have been substantial, but developing real-time systems for perceptual task guidance remains challenging. These systems must provide interactive, proactive assistance based on streaming visual inputs, yet their development is constrained by the costly and labor-intensive process of data collection and system evaluation. To address these limitations, we present a comprehensive framework with three key contributions. First, we introduce a novel data curation pipeline that synthesizes dialogues from annotated egocentric videos, resulting in \dataset, a large-scale synthetic dialogue dataset spanning multiple domains. Second, we develop a suite of automatic evaluation metrics, validated through extensive human studies. Third, we propose an end-to-end model that processes streaming video inputs to generate contextually appropriate responses, incorporating novel techniques for handling data imbalance and long-duration videos. This work lays the foundation for developing real-time, proactive AI assistants capable of guiding users through diverse tasks.
@inproceedings{zhang2025proactive, title = {Proactive Assistant Dialogue Generation from Streaming Egocentric Videos}, author = {Zhang, Yichi and Dong, Xin Luna and Lin, Zhaojiang and Madotto, Andrea and Kumar, Anuj and Damavandi, Babak and Chai, Joyce and Moon, Seungwhan}, booktitle = {arXiv}, year = {2025}, month = jun, }

2024
- CVPR
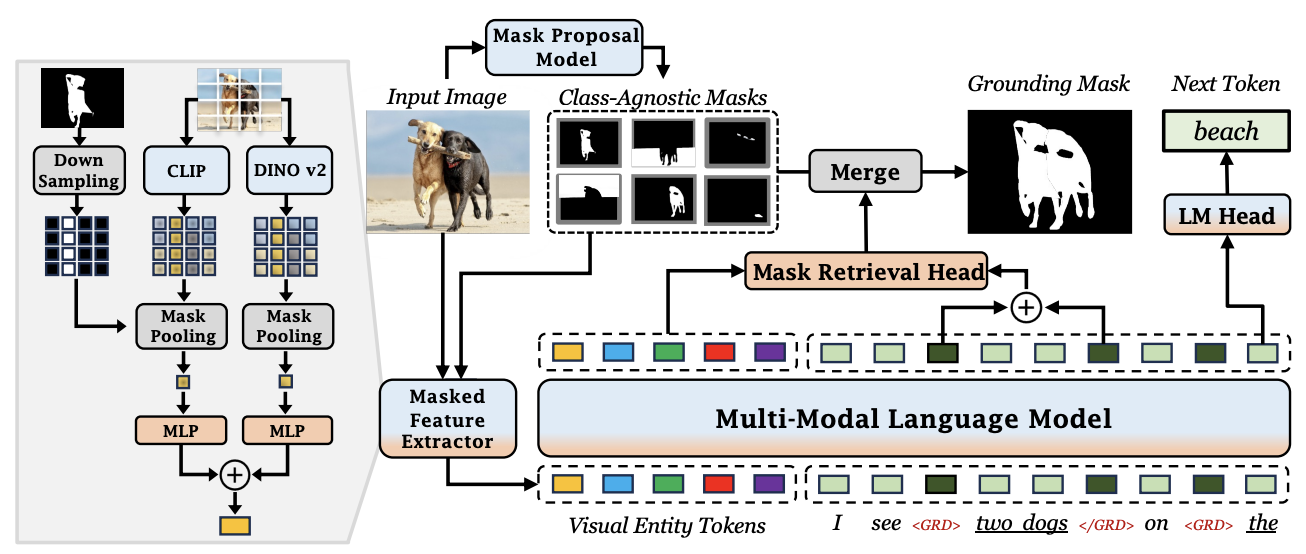 GROUNDHOG: Grounding Large Language Models to Holistic SegmentationYichi Zhang, Ziqiao Ma , Xiaofeng Gao , Suhaila Shakiah , Qiaozi Gao , and Joyce ChaiIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2024
GROUNDHOG: Grounding Large Language Models to Holistic SegmentationYichi Zhang, Ziqiao Ma , Xiaofeng Gao , Suhaila Shakiah , Qiaozi Gao , and Joyce ChaiIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2024Most multimodal large language models (MLLMs) learn language-to-object grounding through causal language modeling where grounded objects are captured by bounding boxes as sequences of location tokens. This paradigm lacks pixel-level representations that are important for fine-grained visual understanding and diagnosis. In this work, we introduce GROUNDHOG, an MLLM developed by grounding Large Language Models to holistic segmentation. GROUNDHOG incorporates a masked feature extractor and converts extracted features into visual entity tokens for the MLLM backbone, which then connects groundable phrases to unified grounding masks by retrieving and merging the entity masks. To train GROUNDHOG, we carefully curated M3G2, a grounded visual instruction tuning dataset with Multi-Modal Multi-Grained Grounding, by harvesting a collection of segmentation-grounded datasets with rich annotations. Our experimental results show that GROUNDHOG achieves superior performance on various language grounding tasks without task-specific fine-tuning, and significantly reduces object hallucination. GROUNDHOG also demonstrates better grounding towards complex forms of visual input and provides easy-to-understand diagnosis in failure cases.
@inproceedings{zhang2024groundhog, title = {GROUNDHOG: Grounding Large Language Models to Holistic Segmentation}, author = {Zhang, Yichi and Ma, Ziqiao and Gao, Xiaofeng and Shakiah, Suhaila and Gao, Qiaozi and Chai, Joyce}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, year = {2024}, pages = {1234--1254}, } - COLM
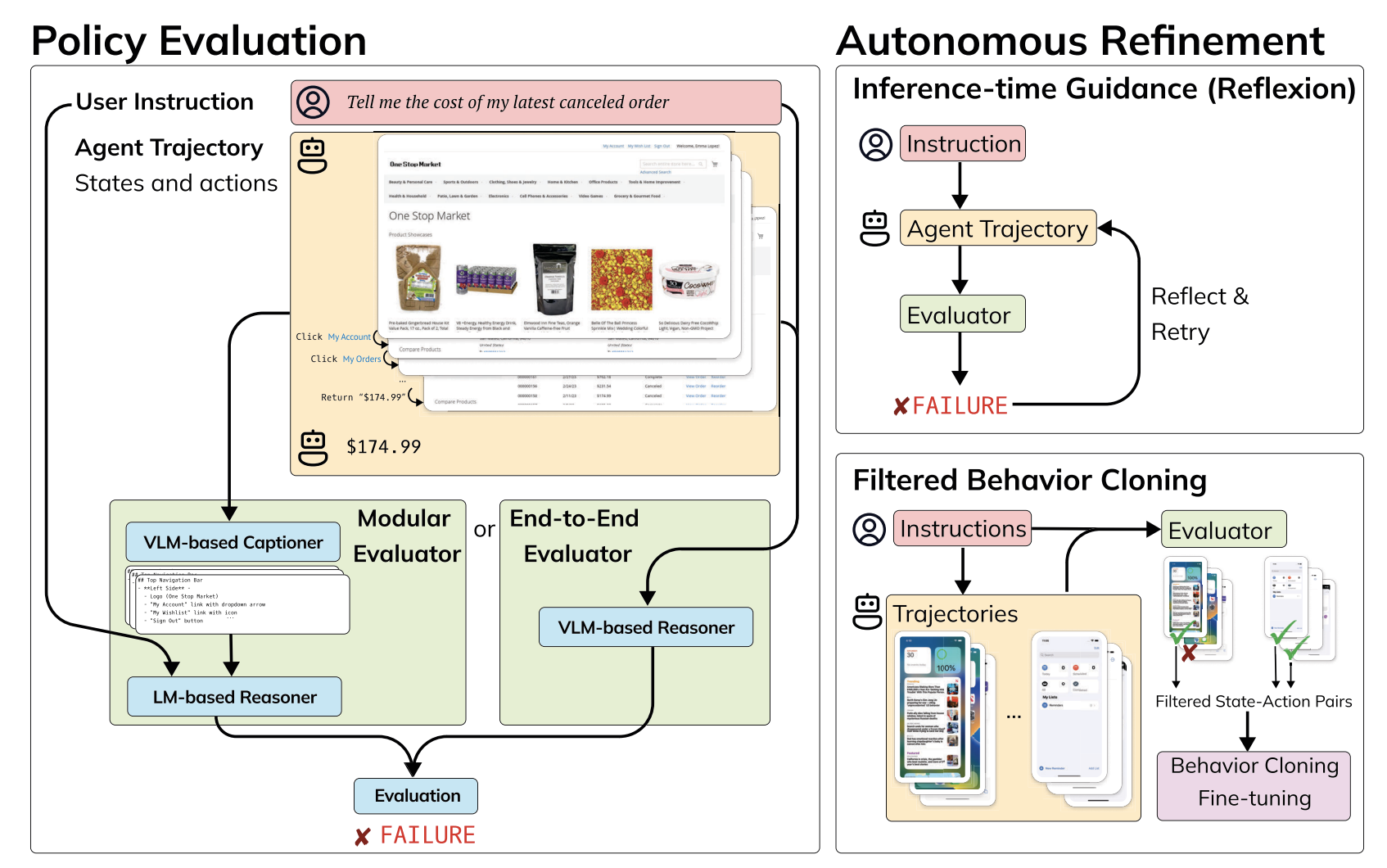 Autonomous evaluation and refinement of digital agentsJiayi Pan , Yichi Zhang, Nicholas Tomlin , Yifei Zhou , Sergey Levine , and Alane SuhrIn First Conference on Language Modeling , Oct 2024
Autonomous evaluation and refinement of digital agentsJiayi Pan , Yichi Zhang, Nicholas Tomlin , Yifei Zhou , Sergey Levine , and Alane SuhrIn First Conference on Language Modeling , Oct 2024We show that domain-general automatic evaluators can significantly improve the performance of agents for web navigation and device control. We experiment with multiple evaluation models that trade off between inference cost, modularity of design, and accuracy. We validate the performance of these models in several popular benchmarks for digital agents, finding between 74.4 and 92.9% agreement with oracle evaluation metrics. Finally, we use these evaluators to improve the performance of existing agents via fine-tuning and inference-time guidance. Without any additional supervision, we improve state-of-the-art performance by 29% on the popular benchmark WebArena, and achieve a 75% relative improvement in a challenging domain transfer scenario.
@inproceedings{pan2024autonomous, title = {Autonomous evaluation and refinement of digital agents}, author = {Pan, Jiayi and Zhang, Yichi and Tomlin, Nicholas and Zhou, Yifei and Levine, Sergey and Suhr, Alane}, booktitle = {First Conference on Language Modeling}, year = {2024}, month = oct, }


2023
- EMNLP
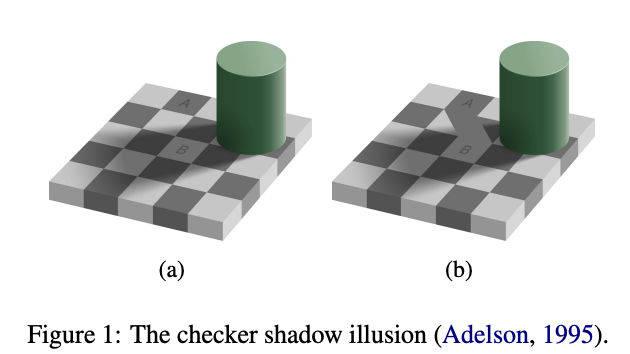 Grounding Visual Illusions in Language: Do Vision-Language Models Perceive Illusions Like Humans?Yichi Zhang, Jiayi Pan , Yuchen Zhou , Rui Pan , and Joyce ChaiIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , Dec 2023
Grounding Visual Illusions in Language: Do Vision-Language Models Perceive Illusions Like Humans?Yichi Zhang, Jiayi Pan , Yuchen Zhou , Rui Pan , and Joyce ChaiIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , Dec 2023Vision-Language Models (VLMs) are trained on vast amounts of data captured by humans emulating our understanding of the world. However, known as visual illusions, human’s perception of reality isn’t always faithful to the physical world. This raises a key question: do VLMs have the similar kind of illusions as humans do, or do they faithfully learn to represent reality? To investigate this question, we build a dataset containing five types of visual illusions and formulate four tasks to examine visual illusions in state-of-the-art VLMs. Our findings have shown that although the overall alignment is low, larger models are closer to human perception and more susceptible to visual illusions. Our dataset and initial findings will promote a better understanding of visual illusions in humans and machines and provide a stepping stone for future computational models that can better align humans and machines in perceiving and communicating about the shared visual world. The code and data are available at [github.com/vl-illusion/dataset](https://github.com/vl-illusion/dataset).
@inproceedings{zhang-etal-2023-grounding, title = {Grounding Visual Illusions in Language: Do Vision-Language Models Perceive Illusions Like Humans?}, author = {Zhang, Yichi and Pan, Jiayi and Zhou, Yuchen and Pan, Rui and Chai, Joyce}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika}, booktitle = {Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.emnlp-main.348}, doi = {10.18653/v1/2023.emnlp-main.348}, pages = {5718--5728}, } - EMNLP Findings
 Can Foundation Models Watch, Talk and Guide You Step by Step to Make a Cake?Yuwei Bao , Keunwoo Yu , Yichi Zhang, Shane Storks , Itamar Bar-Yossef , Alex Iglesia , Megan Su , Xiao Zheng , and Joyce ChaiIn Findings of the Association for Computational Linguistics: EMNLP 2023 , Dec 2023
Can Foundation Models Watch, Talk and Guide You Step by Step to Make a Cake?Yuwei Bao , Keunwoo Yu , Yichi Zhang, Shane Storks , Itamar Bar-Yossef , Alex Iglesia , Megan Su , Xiao Zheng , and Joyce ChaiIn Findings of the Association for Computational Linguistics: EMNLP 2023 , Dec 2023Despite tremendous advances in AI, it remains a significant challenge to develop interactive task guidance systems that can offer situated, personalized guidance and assist humans in various tasks. These systems need to have a sophisticated understanding of the user as well as the environment, and make timely accurate decisions on when and what to say. To address this issue, we created a new multimodal benchmark dataset, Watch, Talk and Guide (WTaG) based on natural interaction between a human user and a human instructor. We further proposed two tasks: User and Environment Understanding, and Instructor Decision Making. We leveraged several foundation models to study to what extent these models can be quickly adapted to perceptually enabled task guidance. Our quantitative, qualitative, and human evaluation results show that these models can demonstrate fair performances in some cases with no task-specific training, but a fast and reliable adaptation remains a significant challenge. Our benchmark and baselines will provide a stepping stone for future work on situated task guidance.
@inproceedings{bao-etal-2023-foundation, title = {Can Foundation Models Watch, Talk and Guide You Step by Step to Make a Cake?}, author = {Bao, Yuwei and Yu, Keunwoo and Zhang, Yichi and Storks, Shane and Bar-Yossef, Itamar and de la Iglesia, Alex and Su, Megan and Zheng, Xiao and Chai, Joyce}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2023}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.findings-emnlp.824}, doi = {10.18653/v1/2023.findings-emnlp.824}, pages = {12325--12341}, }


2022
- EMNLP
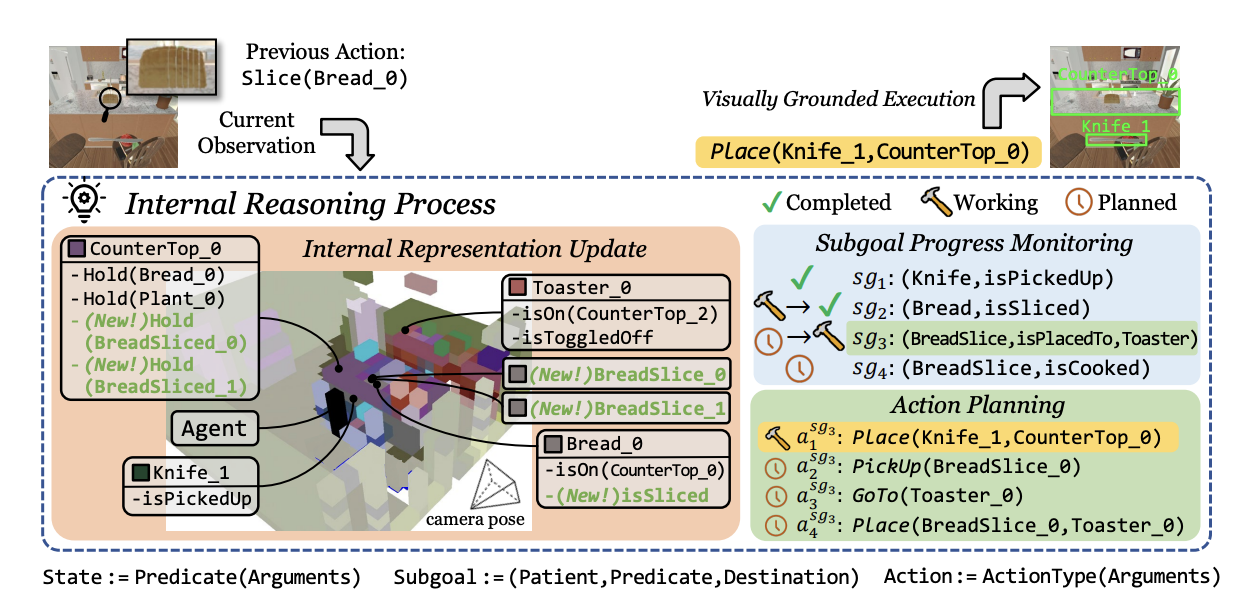 DANLI: Deliberative Agent for Following Natural Language InstructionsYichi Zhang, Jianing Yang , Jiayi Pan , Shane Storks , Nikhil Devraj , Ziqiao Ma , Keunwoo Yu , Yuwei Bao , and Joyce ChaiIn Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , Dec 2022
DANLI: Deliberative Agent for Following Natural Language InstructionsYichi Zhang, Jianing Yang , Jiayi Pan , Shane Storks , Nikhil Devraj , Ziqiao Ma , Keunwoo Yu , Yuwei Bao , and Joyce ChaiIn Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , Dec 2022Recent years have seen an increasing amount of work on embodied AI agents that can perform tasks by following human language instructions. However, most of these agents are reactive, meaning that they simply learn and imitate behaviors encountered in the training data. These reactive agents are insufficient for long-horizon complex tasks. To address this limitation, we propose a neuro-symbolic deliberative agent that, while following language instructions, proactively applies reasoning and planning based on its neural and symbolic representations acquired from past experience (e.g., natural language and egocentric vision). We show that our deliberative agent achieves greater than 70% improvement over reactive baselines on the challenging TEACh benchmark. Moreover, the underlying reasoning and planning processes, together with our modular framework, offer impressive transparency and explainability to the behaviors of the agent. This enables an in-depth understanding of the agent’s capabilities, which shed light on challenges and opportunities for future embodied agents for instruction following. The code is available at \urlhttps://github.com/sled-group/DANLI.
@inproceedings{zhang-etal-2022-danli, title = {{DANLI}: Deliberative Agent for Following Natural Language Instructions}, author = {Zhang, Yichi and Yang, Jianing and Pan, Jiayi and Storks, Shane and Devraj, Nikhil and Ma, Ziqiao and Yu, Keunwoo and Bao, Yuwei and Chai, Joyce}, editor = {Goldberg, Yoav and Kozareva, Zornitsa and Zhang, Yue}, booktitle = {Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing}, month = dec, year = {2022}, address = {Abu Dhabi, United Arab Emirates}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.emnlp-main.83}, doi = {10.18653/v1/2022.emnlp-main.83}, pages = {1280--1298}, }

2021
- ACL Findings
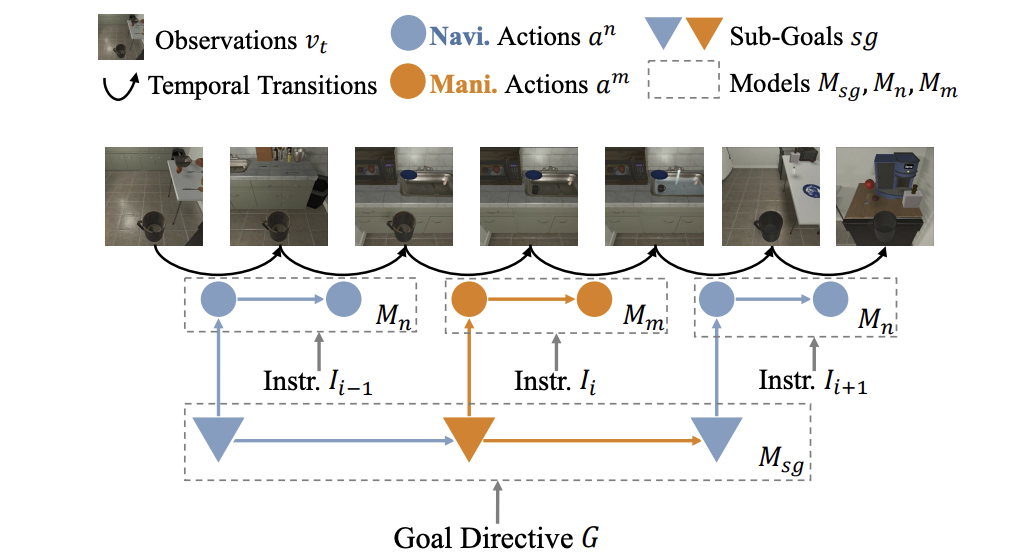 Hierarchical Task Learning from Language Instructions with Unified Transformers and Self-MonitoringYichi Zhang, and Joyce ChaiIn Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , Aug 2021
Hierarchical Task Learning from Language Instructions with Unified Transformers and Self-MonitoringYichi Zhang, and Joyce ChaiIn Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , Aug 2021Despite recent progress, learning new tasks through language instructions remains an extremely challenging problem. On the ALFRED benchmark for task learning, the published state-of-the-art system only achieves a task success rate of less than 10% in an unseen environment, compared to the human performance of over 90%. To address this issue, this paper takes a closer look at task learning. In a departure from a widely applied end-to-end architecture, we decomposed task learning into three sub-problems: sub-goal planning, scene navigation, and object manipulation; and developed a model HiTUT (stands for Hierarchical Tasks via Unified Transformers) that addresses each sub-problem in a unified manner to learn a hierarchical task structure. On the ALFRED benchmark, HiTUT has achieved the best performance with a remarkably higher generalization ability. In the unseen environment, HiTUT achieves over 160% performance gain in success rate compared to the previous state of the art. The explicit representation of task structures also enables an in-depth understanding of the nature of the problem and the ability of the agent, which provides insight for future benchmark development and evaluation.
@inproceedings{zhang2021hierarchical, title = {Hierarchical Task Learning from Language Instructions with Unified Transformers and Self-Monitoring}, author = {Zhang, Yichi and Chai, Joyce}, booktitle = {Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021}, pages = {4202--4213}, year = {2021}, month = aug, } - EACL
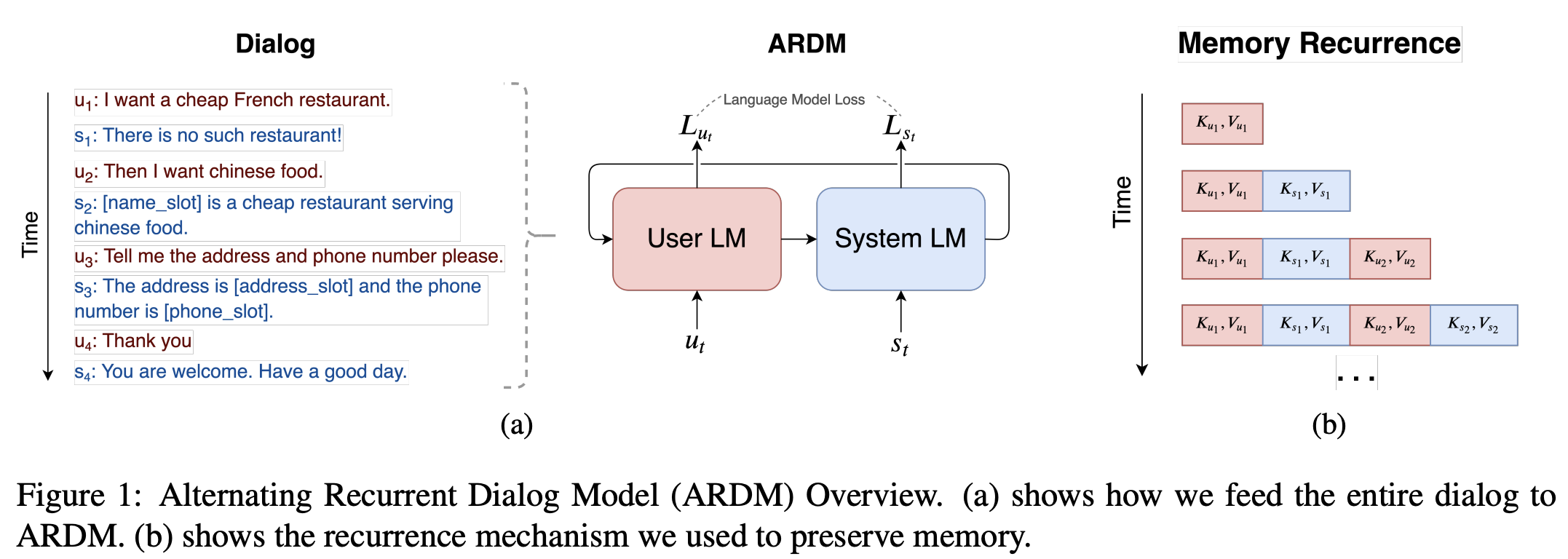 Alternating Recurrent Dialog Model with Large-scale Pre-trained Language ModelsQingyang Wu , Yichi Zhang, Yu Li , and Zhou YuIn Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , Apr 2021
Alternating Recurrent Dialog Model with Large-scale Pre-trained Language ModelsQingyang Wu , Yichi Zhang, Yu Li , and Zhou YuIn Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , Apr 2021Existing dialog system models require extensive human annotations and are difficult to generalize to different tasks. The recent success of large pre-trained language models such as BERT and GPT-2 (Devlin et al., 2019; Radford et al., 2019) have suggested the effectiveness of incorporating language priors in down-stream NLP tasks. However, how much pre-trained language models can help dialog response generation is still under exploration. In this paper, we propose a simple, general, and effective framework: Alternating Recurrent Dialog Model (ARDM). ARDM models each speaker separately and takes advantage of the large pre-trained language model. It requires no supervision from human annotations such as belief states or dialog acts to achieve effective conversations. ARDM outperforms or is on par with state-of-the-art methods on two popular task-oriented dialog datasets: CamRest676 and MultiWOZ. Moreover, we can generalize ARDM to more challenging, non-collaborative tasks such as persuasion. In persuasion tasks, ARDM is capable of generating human-like responses to persuade people to donate to a charity.
@inproceedings{wu-etal-2021-alternating, title = {Alternating Recurrent Dialog Model with Large-scale Pre-trained Language Models}, author = {Wu, Qingyang and Zhang, Yichi and Li, Yu and Yu, Zhou}, editor = {Merlo, Paola and Tiedemann, Jorg and Tsarfaty, Reut}, booktitle = {Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume}, month = apr, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.eacl-main.110}, doi = {10.18653/v1/2021.eacl-main.110}, pages = {1292--1301}, } - EMNLP Findings
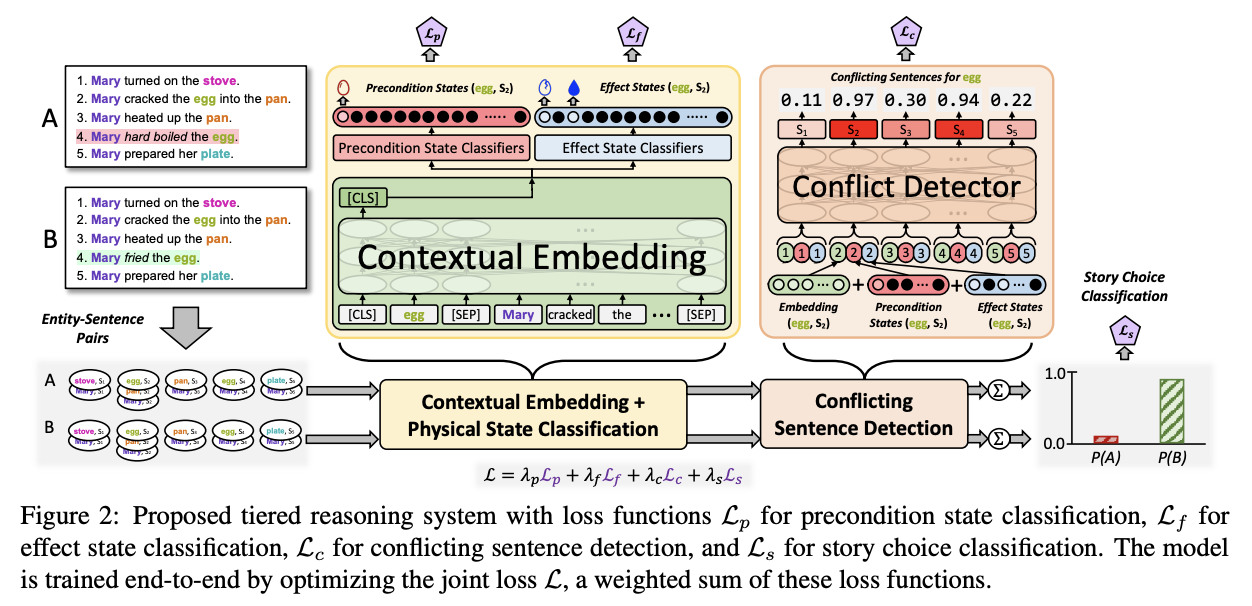 Tiered Reasoning for Intuitive Physics: Toward Verifiable Commonsense Language UnderstandingShane Storks , Qiaozi Gao , Yichi Zhang, and Joyce ChaiIn Findings of the Association for Computational Linguistics: EMNLP 2021 , Nov 2021
Tiered Reasoning for Intuitive Physics: Toward Verifiable Commonsense Language UnderstandingShane Storks , Qiaozi Gao , Yichi Zhang, and Joyce ChaiIn Findings of the Association for Computational Linguistics: EMNLP 2021 , Nov 2021Large-scale, pre-trained language models (LMs) have achieved human-level performance on a breadth of language understanding tasks. However, evaluations only based on end task performance shed little light on machines’ true ability in language understanding and reasoning. In this paper, we highlight the importance of evaluating the underlying reasoning process in addition to end performance. Toward this goal, we introduce Tiered Reasoning for Intuitive Physics (TRIP), a novel commonsense reasoning dataset with dense annotations that enable multi-tiered evaluation of machines’ reasoning process. Our empirical results show that while large LMs can achieve high end performance, they struggle to support their predictions with valid supporting evidence. The TRIP dataset and our baseline results will motivate verifiable evaluation of commonsense reasoning and facilitate future research toward developing better language understanding and reasoning models.
@inproceedings{storks-etal-2021-tiered-reasoning, title = {Tiered Reasoning for Intuitive Physics: Toward Verifiable Commonsense Language Understanding}, author = {Storks, Shane and Gao, Qiaozi and Zhang, Yichi and Chai, Joyce}, editor = {Moens, Marie-Francine and Huang, Xuanjing and Specia, Lucia and Yih, Scott Wen-tau}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2021}, month = nov, year = {2021}, address = {Punta Cana, Dominican Republic}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.findings-emnlp.422}, doi = {10.18653/v1/2021.findings-emnlp.422}, pages = {4902--4918}, } - Applied Sciences
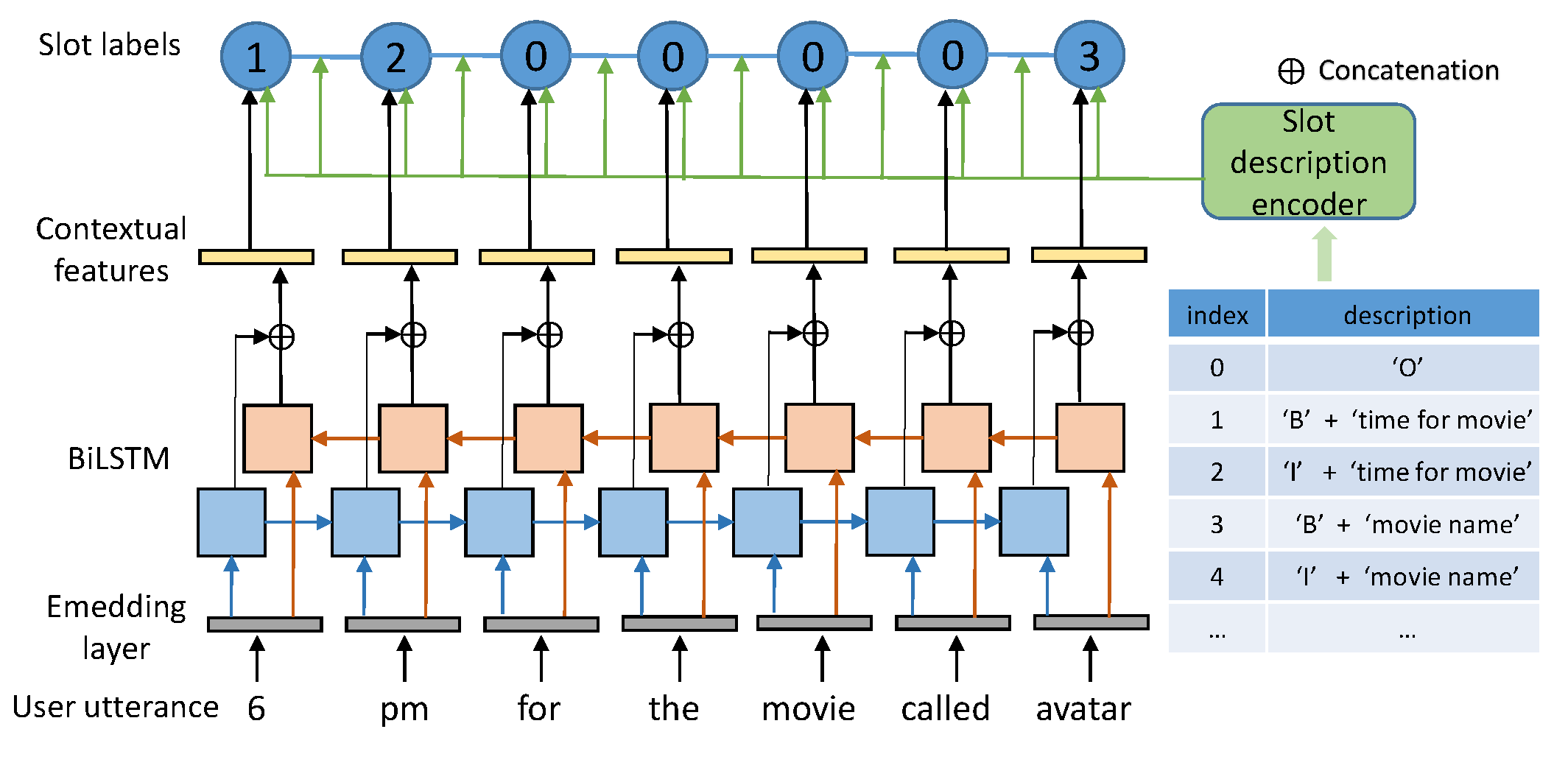 Elastic CRFs for Open-Ontology Slot FillingYinpei Dai , Yichi Zhang, Hong Liu , Zhijian Ou , Yi Huang , and Junlan FengApplied Sciences, Nov 2021
Elastic CRFs for Open-Ontology Slot FillingYinpei Dai , Yichi Zhang, Hong Liu , Zhijian Ou , Yi Huang , and Junlan FengApplied Sciences, Nov 2021Slot filling is a crucial component in task-oriented dialog systems that is used to parse (user) utterances into semantic concepts called slots. An ontology is defined by the collection of slots and the values that each slot can take. The most widely used practice of treating slot filling as a sequence labeling task suffers from two main drawbacks. First, the ontology is usually pre-defined and fixed and therefore is not able to detect new labels for unseen slots. Second, the one-hot encoding of slot labels ignores the correlations between slots with similar semantics, which makes it difficult to share knowledge learned across different domains. To address these problems, we propose a new model called elastic conditional random field (eCRF), where each slot is represented by the embedding of its natural language description and modeled by a CRF layer. New slot values can be detected by eCRF whenever a language description is available for the slot. In our experiment, we show that eCRFs outperform existing models in both in-domain and cross-domain tasks, especially in predicting unseen slots and values.
@article{dai2021elastic, title = {Elastic CRFs for Open-Ontology Slot Filling}, author = {Dai, Yinpei and Zhang, Yichi and Liu, Hong and Ou, Zhijian and Huang, Yi and Feng, Junlan}, journal = {Applied Sciences}, volume = {11}, number = {22}, pages = {10675}, year = {2021}, publisher = {MDPI}, }




2020
- AAAI
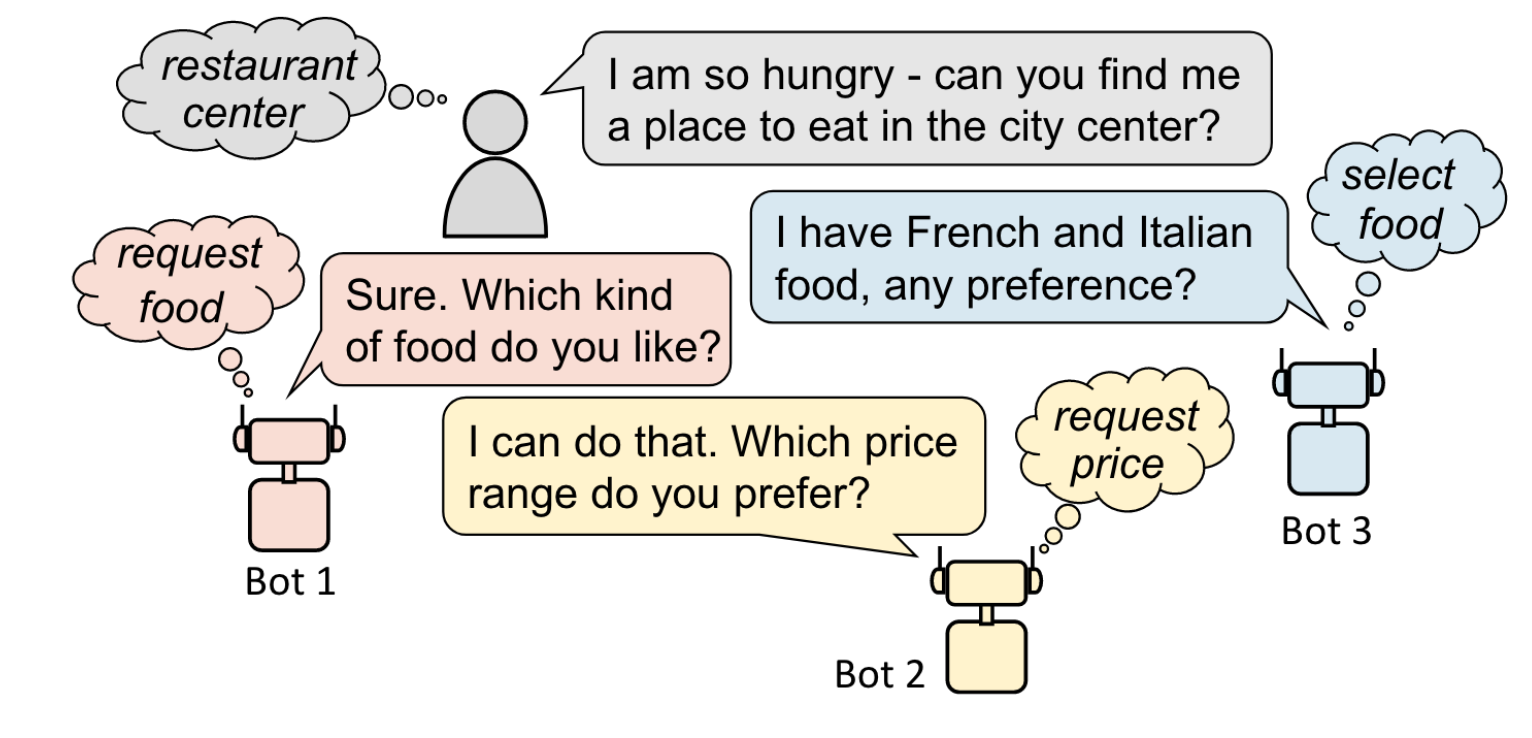 Task-oriented dialog systems that consider multiple appropriate responses under the same contextYichi Zhang, Zhijian Ou , and Zhou YuIn Proceedings of the AAAI Conference on Artificial Intelligence , Jan 2020
Task-oriented dialog systems that consider multiple appropriate responses under the same contextYichi Zhang, Zhijian Ou , and Zhou YuIn Proceedings of the AAAI Conference on Artificial Intelligence , Jan 2020Conversations have an intrinsic one-to-many property, which means that multiple responses can be appropriate for the same dialog context. In task-oriented dialogs, this property leads to different valid dialog policies towards task completion. However, none of the existing task-oriented dialog generation approaches takes this property into account. We propose a Multi-Action Data Augmentation (MADA) framework to utilize the one-to-many property to generate diverse appropriate dialog responses. Specifically, we first use dialog states to summarize the dialog history, and then discover all possible mappings from every dialog state to its different valid system actions. During dialog system training, we enable the current dialog state to map to all valid system actions discovered in the previous process to create additional state-action pairs. By incorporating these additional pairs, the dialog policy learns a balanced action distribution, which further guides the dialog model to generate diverse responses. Experimental results show that the proposed framework consistently improves dialog policy diversity, and results in improved response diversity and appropriateness. Our model obtains state-of-the-art results on MultiWOZ.
@inproceedings{zhang2020task, title = {Task-oriented dialog systems that consider multiple appropriate responses under the same context}, author = {Zhang, Yichi and Ou, Zhijian and Yu, Zhou}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {34}, number = {05}, pages = {9604--9611}, year = {2020}, month = jan, } - ACL
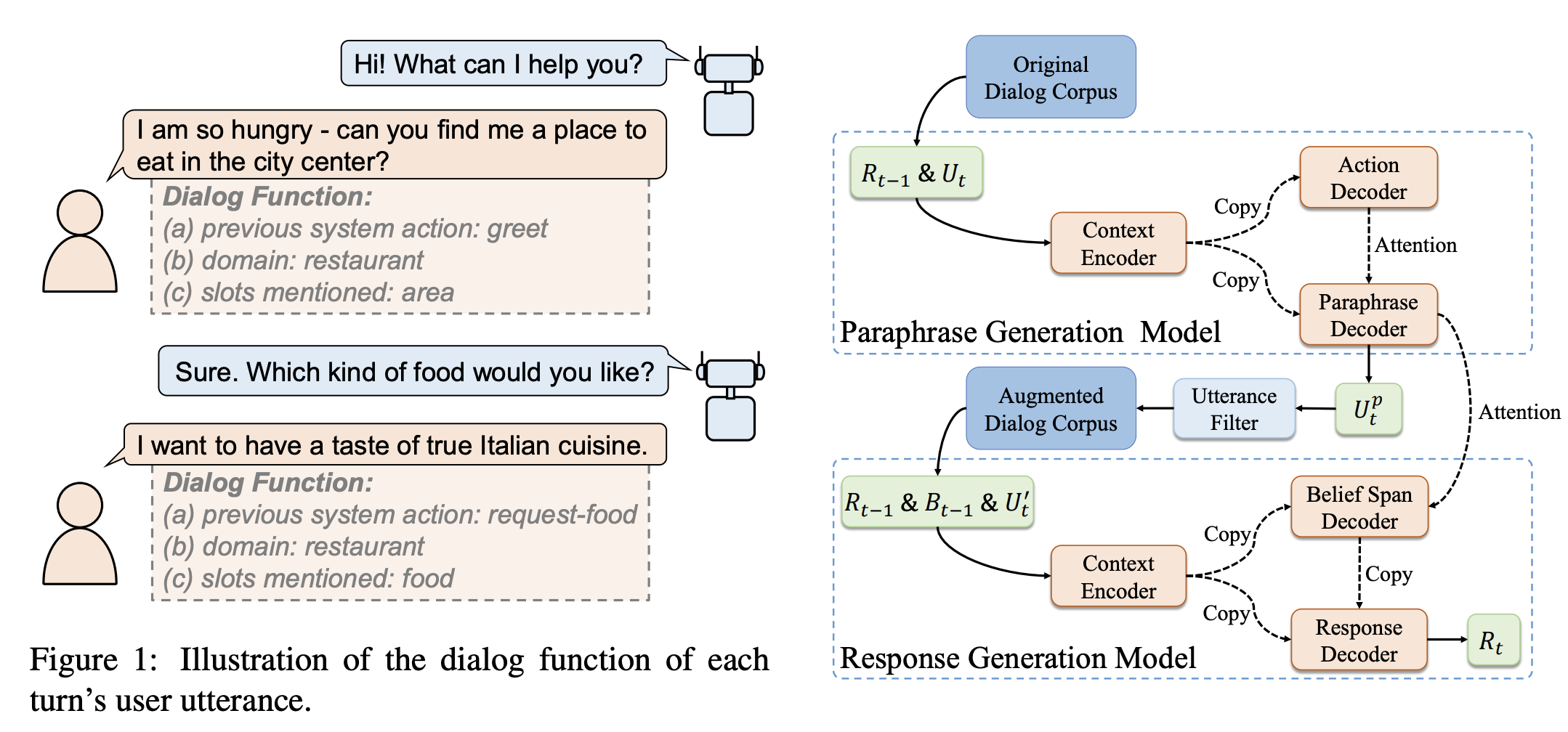 Paraphrase Augmented Task-Oriented Dialog GenerationSilin Gao , Yichi Zhang, Zhijian Ou , and Zhou YuIn Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , Jul 2020
Paraphrase Augmented Task-Oriented Dialog GenerationSilin Gao , Yichi Zhang, Zhijian Ou , and Zhou YuIn Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , Jul 2020Neural generative models have achieved promising performance on dialog generation tasks if given a huge data set. However, the lack of high-quality dialog data and the expensive data annotation process greatly limit their application in real world settings. We propose a paraphrase augmented response generation (PARG) framework that jointly trains a paraphrase model and a response generation model to improve the dialog generation performance. We also design a method to automatically construct paraphrase training data set based on dialog state and dialog act labels. PARG is applicable to various dialog generation models, such as TSCP (Lei et al., 2018) and DAMD (Zhang et al., 2019). Experimental results show that the proposed framework improves these state-of-the-art dialog models further on CamRest676 and MultiWOZ. PARG also outperforms other data augmentation methods significantly in dialog generation tasks, especially under low resource settings.
@inproceedings{gao-etal-2020-paraphrase, title = {Paraphrase Augmented Task-Oriented Dialog Generation}, author = {Gao, Silin and Zhang, Yichi and Ou, Zhijian and Yu, Zhou}, editor = {Jurafsky, Dan and Chai, Joyce and Schluter, Natalie and Tetreault, Joel}, booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics}, month = jul, year = {2020}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2020.acl-main.60}, doi = {10.18653/v1/2020.acl-main.60}, pages = {639--649}, } - EMNLP
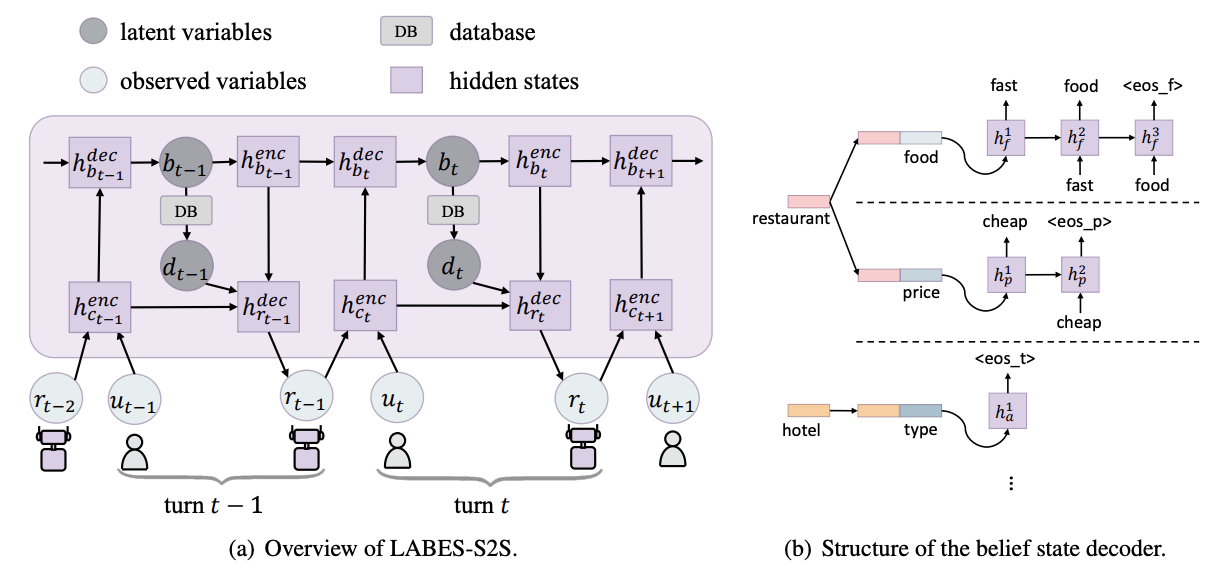 A Probabilistic End-To-End Task-Oriented Dialog Model with Latent Belief States towards Semi-Supervised LearningYichi Zhang, Zhijian Ou , Min Hu , and Junlan FengIn Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , Nov 2020
A Probabilistic End-To-End Task-Oriented Dialog Model with Latent Belief States towards Semi-Supervised LearningYichi Zhang, Zhijian Ou , Min Hu , and Junlan FengIn Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , Nov 2020Structured belief states are crucial for user goal tracking and database query in task-oriented dialog systems. However, training belief trackers often requires expensive turn-level annotations of every user utterance. In this paper we aim at alleviating the reliance on belief state labels in building end-to-end dialog systems, by leveraging unlabeled dialog data towards semi-supervised learning. We propose a probabilistic dialog model, called the LAtent BElief State (LABES) model, where belief states are represented as discrete latent variables and jointly modeled with system responses given user inputs. Such latent variable modeling enables us to develop semi-supervised learning under the principled variational learning framework. Furthermore, we introduce LABES-S2S, which is a copy-augmented Seq2Seq model instantiation of LABES. In supervised experiments, LABES-S2S obtains strong results on three benchmark datasets of different scales. In utilizing unlabeled dialog data, semi-supervised LABES-S2S significantly outperforms both supervised-only and semi-supervised baselines. Remarkably, we can reduce the annotation demands to 50% without performance loss on MultiWOZ.
@inproceedings{zhang-etal-2020-probabilistic, title = {A Probabilistic End-To-End Task-Oriented Dialog Model with Latent Belief States towards Semi-Supervised Learning}, author = {Zhang, Yichi and Ou, Zhijian and Hu, Min and Feng, Junlan}, editor = {Webber, Bonnie and Cohn, Trevor and He, Yulan and Liu, Yang}, booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)}, month = nov, year = {2020}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2020.emnlp-main.740}, doi = {10.18653/v1/2020.emnlp-main.740}, pages = {9207--9219}, } - INTERSPEECH
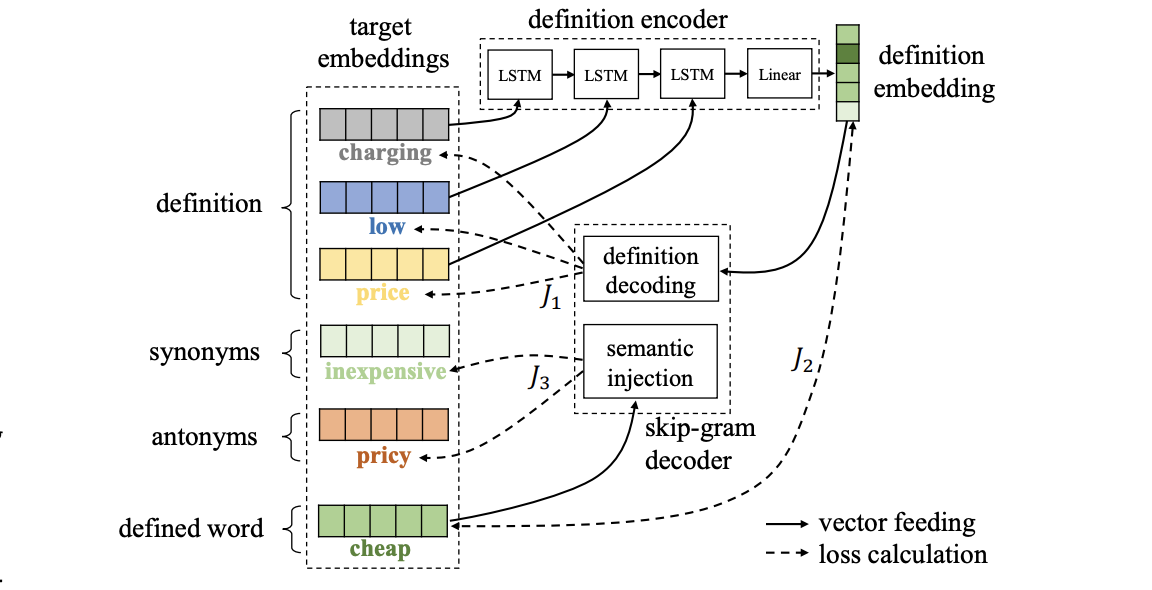 Improved Learning of Word Embeddings with Word Definitions and Semantic Injection.Yichi Zhang, Yinpei Dai , Zhijian Ou , Huixin Wang , and Junlan FengIn INTERSPEECH , Nov 2020
Improved Learning of Word Embeddings with Word Definitions and Semantic Injection.Yichi Zhang, Yinpei Dai , Zhijian Ou , Huixin Wang , and Junlan FengIn INTERSPEECH , Nov 2020Recently, two categories of linguistic knowledge sources, word definitions from monolingual dictionaries and linguistic relations (e.g. synonymy and antonymy), have been leveraged separately to improve the traditional co-occurrence based methods for learning word embeddings. In this paper, we investigate to leverage these two kinds of resources together. Specifically, we propose a new method for word embedding specialization, named Definition Autoencoder with Semantic Injection (DASI). In our experiments, DASI outperforms its single-knowledge-source counterparts on two semantic similarity benchmarks, and the improvements are further justified on a downstream task of dialog state tracking. We also show that DASI is superior over simple combinations of existing methods in incorporating the two knowledge sources.
@inproceedings{zhang2020improved, title = {Improved Learning of Word Embeddings with Word Definitions and Semantic Injection.}, author = {Zhang, Yichi and Dai, Yinpei and Ou, Zhijian and Wang, Huixin and Feng, Junlan}, booktitle = {INTERSPEECH}, pages = {4253--4257}, year = {2020}, }



